Fooled by Randomness in Cold Email: Why 'This One Variable Changed Everything' Is Almost Certainly Wrong

I was reading Nassim Taleb's “Fooled by Randomness” when it hit me. I had been consuming cold email advice on LinkedIn for months. Every week, another post: “I changed my subject line and doubled my open rate.” “This one CTA increased replies by 97%.” “The exact template that booked me 40 meetings.”
I was never fully sold on any of it. Something always felt off. But I couldn't articulate why until Taleb gave me the framework.
The cold email optimization industry has a statistical literacy problem. People are drawing massive conclusions from tiny datasets, ignoring every variable they can't control, and presenting random outcomes as proven strategies.
And AI is making it worse—because most people are deploying AI on the least impactful variable (copy tweaks) when the data says they should be using it for targeting, persistence, and volume.
Here is everything the data actually says.
Quick Answer
No single variable determines cold email success. Data from 28M+ emails shows that targeting quality, send volume, and persistence matter far more than subject lines or copy tweaks. Most “this one change” claims are survivorship bias.
The Problem: Survivorship Bias in Cold Email Advice
Taleb's central insight is brutal and simple: “The highest performing realization will be the most visible. Why? Because the losers do not show up.”
When someone posts that they changed one variable and 10x'd their results, you are hearing from one person. The hundreds who made the same change and saw no difference never write a LinkedIn post about it. Nobody shares “I tried the exact template from that viral post and nothing happened.”
This is textbook survivorship bias.
Taleb tears apart the book “The Millionaire Next Door” for studying only rich people, cataloguing their habits, and presenting those habits as the cause of their success. The authors never looked at everyone with the same habits who failed. The cold email advice industry does the exact same thing. Study the campaigns that worked. Identify a variable. Declare it the cause.
He puts it plainly: “One cannot consider anything—like the success of those in a profession—without taking into account the average of the people who enter it, not the sample of those who have succeeded in it.”
The Monkey Metaphor
One of Taleb's best analogies: put enough monkeys in front of typewriters and eventually one will produce the Iliad. But you would never hire that monkey to write the Odyssey.
Put enough cold emailers in a room trying the same tactic, and someone will get spectacular results by pure chance. That person writes the blog post. Gets the LinkedIn engagement. Starts selling a course.
It looks like skill. It is indistinguishable from luck.
Why This Matters Practically
“Mild success can be explainable by skills and labor. Wild success is attributable to variance.”
The person consistently booking 5-8 meetings per week probably has a solid process. The person claiming 40 meetings from a single template change probably got lucky and cannot replicate it. The more extreme the claimed result, the more skeptical you should be.
“That which came with the help of luck could be taken away by luck (and often rapidly and unexpectedly at that).”
Lucky wins are fragile. A system that generates consistent, moderate results is far more valuable than a one-time spike you cannot explain or reproduce.
The Math Problem: Why Most Cold Email “Tests” Prove Nothing
Even if you wanted to run a real A/B test on cold email, the math works against you.
The Variables You Cannot Control
Every time someone says “I changed one variable and results changed,” they are ignoring roughly 20 confounders they have zero control over.
What you control (partially): subject line, opener, body copy, CTA, sender name and title, send time and day, follow-up cadence, email length, personalization depth, deliverability setup, domain reputation.
What you do not control: the prospect's current pain level, their budget cycle, how full their inbox is that day, their mood, competing priorities, whether they just got five other cold emails about the same thing, whether they are actively evaluating solutions, seasonal effects, whether they are on vacation or in back-to-back meetings.
Any “A/B test” claiming to isolate one variable is operating in a system with 19+ uncontrolled confounders. That is not a test. That is a guess.
Sample Size Requirements
Here is where it gets uncomfortable. Using standard statistical parameters (95% confidence, 80% power), here is what you actually need:
| Baseline Reply Rate | Lift to Detect | Emails Per Variation | Total Needed |
|---|---|---|---|
| 3% (industry avg) | 50% relative (to 4.5%) | ~2,400 | ~4,800 |
| 5% | 20% relative (to 6%) | ~4,800 | ~9,600 |
| 5% | 50% relative (to 7.5%) | ~770 | ~1,540 |
| 10% | 20% relative (to 12%) | ~1,800 | ~3,600 |
Most cold emailers “test” with 100-500 emails per variation. At a 3% baseline reply rate, that gives you 3-15 replies per variant. You cannot conclude anything from 3-15 data points.
HubSpot recommends at least 20,000 recipients for reliable A/B test results. Most cold email operations send 500-2,000 emails per month total.
Proper Test vs. How Cold Emailers “Test”
| Requirement | Proper A/B Test | Typical Cold Email “Test” |
|---|---|---|
| Sample size | 1,000-20,000+ per variant | 50-300 per variant |
| Randomization | True random assignment | Split by list segment or time |
| Variables | One changed, rest constant | “I rewrote the email” (changed everything) |
| Pre-registration | Hypothesis defined before test | “Let me try and see” |
| No peeking | Results checked after full sample | Checked daily, stopped early |
| Confidence interval | 95% confidence, 80% power | No statistical analysis at all |
| Replication | Reproduced across multiple tests | One test declared definitive |
The Peeking Problem
From Evan Miller's “How Not to Run an A/B Test”: most cold emailers check results repeatedly and stop when they see a “winner.” This destroys statistical validity. If you peek at an ongoing experiment 10 times, what you think is 1% significance is actually 5%.
The significance calculation assumes the sample size was fixed in advance. “Run until we see a difference” makes all significance levels meaningless.
Real Examples of Dubious Claims
Mailshake's “97% More Appointments” case study: Changed two elements simultaneously. Tested on 206 prospects. Variation A got around 20 replies. Variation B got around 37. No control group. No confounding variable controls. No significance calculation. Published as proof.
Sales community post “How One Line Doubled My Response Rate”: Went from 9.1% to 24.7% on LinkedIn outreach. Sample: 110 messages split into roughly 55 per variant. You cannot prove anything at any significance threshold with 55 messages per group.
The Fundamental Impossibility
Most cold email operations cannot run statistically valid A/B tests even if they wanted to. At 500 emails per month to a targeted ICP, you would need 4-10 months for a single valid test. By then, the market has changed, your ICP has shifted, and the results are stale.
The entire “test and optimize” framework that cold email gurus sell is built on a statistical impossibility for the vast majority of their audience.
What Actually Drives Cold Email Results: The Impact Hierarchy
Here is what the large-scale studies actually show. Not 200-email “case studies”—real data from tens of millions of emails.
Sources: Gong (28M emails), Woodpecker (20M emails), Instantly (billions of emails), Backlinko (12M emails), Belkins (16.5M emails).
Tier 1: Targeting and List Quality (Biggest Impact)
This is where results live or die.
- Campaigns targeting cohorts of 50 or fewer contacts: 5.8% reply rate vs. 2.1% for blasts of 1,000+ (2.76x lift)
- Verified email lists produce roughly 2x the reply rate of unverified lists
- Top 10% of reps land 8.1x more meetings than average, according to Gong. Copy alone cannot explain an 8x gap. These reps are targeting better.
- Contacting 1-2 people per company: 7.8% reply rate. Contacting 10+: 3.8%
The single biggest lever you have is who you email. Not what you say.
Tier 2: Deliverability and Technical Infrastructure
If your emails do not reach the inbox, nothing else matters.
- Top performers: bounce rate under 1.5%. Bottom performers: 12%+ (Instantly)
- SPF, DKIM, DMARC authentication, domain warm-up, inbox rotation—these are table stakes, not optimizations
Tier 3: Follow-Up Cadence and Persistence
This is where most people quit too early and leave results on the table.
| Stat | Source |
|---|---|
| 4-7 email sequences: 27% reply rate vs. 9% for 1-3 emails | Growth List |
| 80% of sales require 5+ follow-ups | Growth List |
| 92% of reps quit after 4 attempts | Profit Outreach |
| 70% of cold emails have zero follow-up | Growth List |
| First follow-up increases replies by 49-66% | Belkins, Growth List |
| No single email generated >18% of total leads | Ambition |
| The 8th email generated as many new leads as the 2nd | Ambition |
| Average: 306 emails required to acquire one B2B lead | Growth List |
| Average rep needs 344 emails to land one meeting | Gong |
Read that again: the 8th email in a sequence generated as many new leads as the 2nd. And 92% of reps have already quit by attempt number 4.
The math here is overwhelming. Most cold emailers are optimizing copy on emails 1 and 2 while ignoring that emails 5 through 8 contain a massive chunk of their potential results.
Tier 4: Personalization Depth
- Advanced personalization: 17% reply rate vs. 7% without (143% lift)
- Timeline hooks like funding rounds, hiring signals, or product launches: 10.01% vs. 4.39% for generic messages (2.3x lift)
Tier 5: Copy Elements (What Gurus Obsess Over)
And here we are. The thing most cold email gurus sell courses about sits at the bottom of the impact stack.
- Emails under 80 words perform best
- Interest-based CTAs outperform meeting requests
- “Thoughts?” as a CTA decreases bookings by 20% (Gong)
- ROI language decreases success by 15% (Gong)
These are real but marginal gains. The difference between a good CTA and a great CTA is a few percentage points. The difference between targeting 50 people vs. blasting 1,000 is a 2.76x multiplier.
One is an optimization. The other is a strategic shift. Gurus sell the optimization because it is easy to teach and easy to sell. The strategic shift requires more work.
Volume as the Antidote to Randomness
Taleb's framework points directly at the solution.
“Very long sample paths end up resembling each other... time will eventually remove the effects of randomness.”
A single cold email tells you nothing. A hundred start showing a pattern. A thousand reveal the actual response rate. The randomness gets averaged out.
This is the law of large numbers applied to outbound. The more reps you do, the less randomness affects your results. Instead of agonizing over whether version A or version B of your subject line is “better” based on 50 emails, send 5,000 emails with a solid process and let the results converge to the true mean.
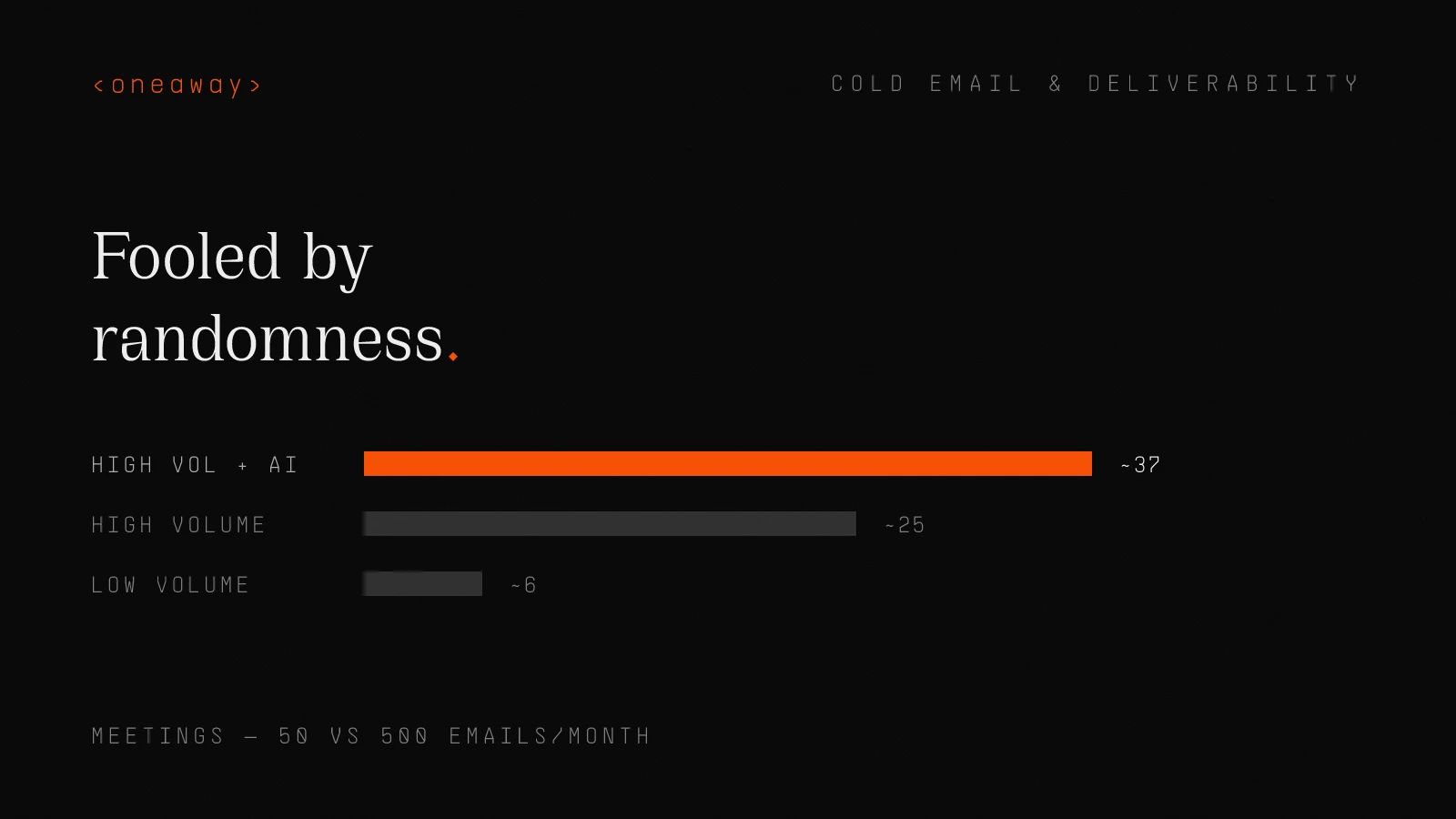
The Numbers Tell the Story
| Scenario | Volume | Reply Rate | Responses | Meetings |
|---|---|---|---|---|
| Low volume, high personalization | 50/month | 25% | 12.5 | ~6 |
| High volume, moderate personalization | 500/month | 10% | 50 | ~25 |
| High volume + AI personalization | 500/month | 15% | 75 | ~37 |
A 25% response rate on 50 emails generates less pipeline than a 10% rate on 500. And when you add AI-powered personalization to high volume, the gap widens further.
The old “quality vs. quantity” debate was a real constraint when the bottleneck was human time. You had to choose: 50 deeply researched emails or 500 generic ones.
That constraint is gone.
Where AI Actually Belongs in This Stack
Here is where most people get it backwards.
The majority of AI cold email tools focus on Tier 5—copy optimization. “AI-powered subject line generator.” “Let AI write your cold emails.” “Personalize your opening line with AI.”
That is deploying your most powerful tool on your least impactful variable.
Where AI should be deployed, based on the impact hierarchy:
Tier 1 (Targeting): AI can research prospects, identify buying signals, score leads based on fit, analyze company data, and build hyper-targeted lists of 50 or fewer contacts per campaign. This is where the 2.76x multiplier lives.
Tier 2 (Deliverability): AI can monitor bounce rates, rotate sending domains, manage warm-up schedules, and flag deliverability issues before they tank your campaigns.
Tier 3 (Persistence): AI can manage multi-step sequences, personalize follow-ups based on non-response patterns, schedule touches across time zones, and ensure no lead falls through the cracks. This is where the 3x multiplier from 4-7 email sequences lives.
Tier 4 (Personalization): AI can reference funding rounds, hiring signals, product launches, and LinkedIn activity at scale. What used to take 15 minutes per prospect now takes 10 seconds.
Tier 5 (Copy): AI can write and iterate on copy. Fine. But this should be the last thing you automate, not the first.
The Productivity Shift
The numbers on AI in outbound are real:
- Manual personalization of 1,000 prospects: ~250 hours and ~$7,500. AI-assisted: 2 hours of setup, $15 in API costs, and 8 hours of review. Roughly 10x cheaper, and often better quality.
- AI-powered tools enable 300+ personalized emails daily per rep, compared to 20-30 manually
- AI campaigns show 57% higher open rates and 82% more responses vs. non-AI campaigns
- 67% of decision-makers do not mind if AI wrote their cold email
- Recipients correctly identify AI-written emails only about 50% of the time—the same as a coin flip
AI eliminates the quality-vs-quantity tradeoff. That is its real value. Not writing better subject lines.
The 7-Month Follow-Up: A Real Example
I want to ground all of this in something that actually happened to me.
There was a point where my business was about to fall apart. Revenue was drying up. I was close to shutting down.
But I had been following up with one lead for seven months. Not because I had some magic email template. Not because I read a post about the perfect follow-up sequence. Just because he never said no. He kept saying “try me again.”
So I kept trying.
When I was at the breaking point, he finally replied and said he was free to chat. I closed him. And he had a referral ready right there. I closed two deals in what felt like one day.
But it was really seven months of persistent work.
No subject line optimization did that. No A/B test. No guru template. Seven months of showing up.
That is Tier 3 in action. And it is exactly the kind of advantage that scales with AI—because AI never forgets to follow up, never gets discouraged, and never decides “this lead is dead” after two attempts.
Frequently Asked Questions
Does A/B testing cold emails work at all?
It can, but only at scale. If you are sending fewer than 5,000 emails per variation, your results are not statistically significant. For most cold email operations, running a proper A/B test is mathematically impossible given their volume. Focus on the higher-impact tiers instead: targeting, deliverability, and persistence.
What is the average cold email reply rate in 2025-2026?
Based on the largest studies available: Belkins reports 5.8% across 16.5M emails (down 15% from 6.8% the prior year). Instantly reports 3.43% average across billions of emails, with the top 10% achieving 10.7%+. The average B2B professional receives 121 emails per day, which explains the declining trend.
How many follow-up emails should I send?
The data strongly supports 4-7 emails per sequence. Sequences of 4-7 emails achieve a 27% reply rate compared to 9% for sequences of 1-3 emails. The 8th email in a sequence generates as many new leads as the 2nd. Most of your results are hiding in the follow-ups that most people never send.
Is personalization or volume more important?
Both, and AI makes it a false choice. High volume (500+ per month) with moderate personalization generates more pipeline than low volume (50 per month) with deep personalization. AI-powered personalization at scale produces the best results of all. The old quality-vs-quantity debate was a constraint of human time, not a strategic truth.
What should I use AI for in cold email?
Deploy AI on the highest-impact variables first: building targeted prospect lists (Tier 1), managing deliverability (Tier 2), automating persistent multi-step follow-up sequences (Tier 3), and personalizing at scale with real buying signals (Tier 4). Copy optimization (Tier 5) should be the last priority, not the first.
How do I know if a cold email case study is credible?
Ask three questions: What was the sample size? (Anything under 1,000 per variation is suspect.) Were variables truly isolated? (If they changed multiple things, the “test” proves nothing.) Is there a statistical significance calculation? (If not, the results are anecdotal.) Most published case studies fail all three checks.
Key Takeaways
- Survivorship bias dominates cold email advice. You only see posts from people whose campaigns worked. The thousands who tried the same thing and failed are invisible. Taleb's framework: “The losers do not show up.”
- Most cold email A/B tests are statistically meaningless. You need 4,800+ emails per variation to detect a 50% lift at a 3% baseline. Most “tests” use 100-500. The conclusions drawn are noise, not signal.
- The impact hierarchy is clear. From 28M+ emails of data: targeting > deliverability > persistence > personalization > copy tweaks. The thing most people optimize (copy) has the least impact.
- Volume is the antidote to randomness. The law of large numbers says: more reps, more predictable results. Instead of perfecting one email, send thousands with a solid system.
- AI belongs on the high-impact tiers. Most people use AI for copy (Tier 5). Deploy it on targeting, deliverability, persistence, and personalization first (Tiers 1-4—where the multipliers live).
- Persistence wins. 4-7 email sequences get 27% reply rates vs. 9% for 1-3 emails. The 8th email generates as many leads as the 2nd. And 92% of reps have already quit by attempt 4.
Building predictable outbound systems is what we do at <oneaway>. If you're a B2B company looking to book more meetings without relying on luck, let's talk.
Continue Reading
What Most Teams Get Wrong About Cold Email Infrastructure
Most teams obsess over copy while their emails land in spam. Here's what actually matters in your cold email infrastructure—from someone who's built it dozens of times.
Read more [ 10 MIN READ ]Best Cold Email Software in 2026 (Ranked by Deliverability)
Most lists rank cold email software by price. Wrong filter. We sent 1.5M+ cold emails — here are the best tools in 2026, ranked by what actually protects deliverability at scale.
Read more [ 11 MIN READ ]Best Cold Email Agencies in 2026 (Ranked by Results)
Most 'best cold email agency' lists are pay-to-play. This one's ranked by results, transparency, and model fit — with five honest competitors and who each is actually best for.
Read more